近日,在IEEE国际多媒体与博览会会议International Conference on Multimedia and Expo(CCF-B类会议oral)ICME 2025公布的录用结果中,我校计算机与人工智能学院多模态视频理解团队的论文入选。此次被录用的论文为“弥合一对多差异:基于多标签语义学习与中继的视频描述生成算法。”(Bridging the One-to-Many Gap: Multi-label Semantic Learning and Relay for Video Captioning.)。该研究成果由我校与湖北师范大学联合培养的22级电子信息硕士研究生胡一康完成,杨莉教授、陈淑琴博士、余良俊教授和武汉理工大学钟教授联合指导,湖北第二师范学院为第一署名单位。

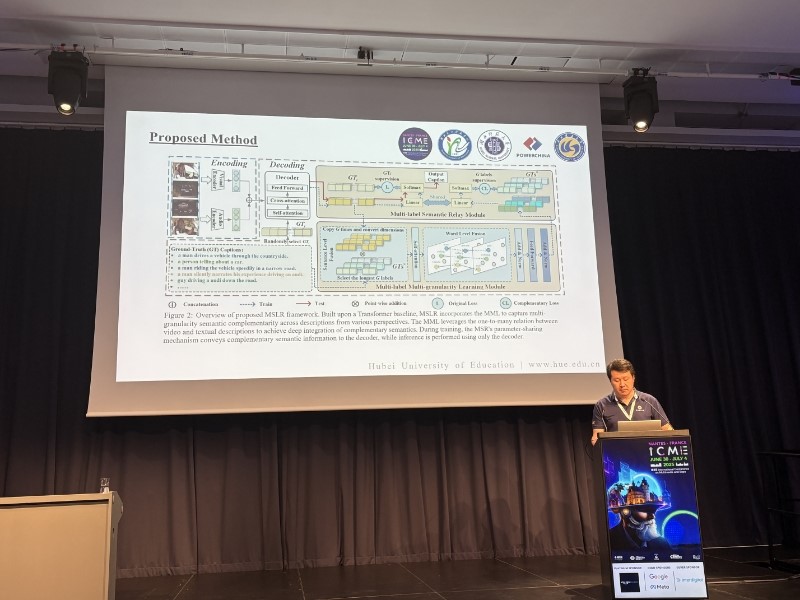
该项研究成果在国际上首次将视频与其描述之间的一对多关系转换为一对一映射模式,创新性地提出了一种多标签语义学习与中继框架,该框架可利用多个字幕的句子级和词级特征来捕获多层次粒度的语义互补性与构建参数共享机制从而解决视频字幕生成中的语义损失问题。实验结果表明此方法超越了当前该领域的先进方法,具有优异的视频字幕生成性能。
2025年,ICME主办地为法国南特,投稿量 3737篇,录用文章 1022篇,录用率为 27.3%,其中oral 153篇。IEEE ICME是计算机多媒体领域最重要和权威的两大国际旗舰会议之一,至今已连续举办26届。